Managing memory usage can be crucial for decent performance in game development, especially on memory-constrained devices like mobile phones or consoles. It’s usually best to allocate what you need up-front at startup or on level load rather than mid-game during a frame, because the default memory allocators can be slow at finding free memory blocks. Constructing objects can also be time consuming depending on the complexity of your classes.
In a garbage collected, managed language like C# you still have to worry about this. You don’t know when the garbage collector is going to clean up objects that are no longer referenced in order to reclaim unused memory. If you allocate objects regularly every frame that quickly become unused and unreferenced, you’ll probably cause regular hitches in your framerate. Also in Unity the Instantiate function call can take quite a bit of CPU time.
One technique we can use to avoid these issues is called “object pooling”. Let’s say you want to spawn a firework particle effect:

Instead of instantiating the prefab whenever you need it, you could pre-instantiate a list of them and disable them. Then when you need to spawn a new firework, go through the list, find one that isn’t enabled, enable it, configure its position, and play it. When it finishes, disable it. This way you re-use firework effects instead of continually creating new objects and destroying them later.
A First Attempt
A first pass on a system like this might look as follows:
using UnityEngine;
using System.Collections.Generic;
public class BasicObjectPool : MonoBehaviour
{
// Prefab for this object pool
public GameObject m_prefab;
// Size of this object pool
public int m_size;
public void Awake()
{
// Instantiate the pooled objects and disable them.
for (var i = 0; i < m_size; i++)
{
var pooledObject = Instantiate(m_prefab, transform);
pooledObject.gameObject.SetActive(false);
}
}
// Returns an object from the pool. Returns null if there are no more
// objects free in the pool.
public GameObject Get()
{
if (transform.childCount == 0)
return null;
return transform.GetChild(0).gameObject;
}
// Returns an object to the pool.
public void ReturnObject(GameObject pooledObject)
{
// Reparent the pooled object to us and disable it.
var pooledObjectTransform = pooledObject.transform;
pooledObjectTransform.parent = transform;
pooledObjectTransform.localPosition = Vector3.zero;
pooledObject.gameObject.SetActive(false);
}
}
Note that our Get method returns null if there are no more objects in the pool. We could also dynamically increase the size of the pool here, but that defeats the purpose of pre-allocating the objects. It’s up to the code calling Get to check if no object is available and handle that situation. In practice you would pick a pool size that adequately covers the maximum number of objects you would like to have available at any one time. It’s not feasible to just keep spawning objects – you’ll run out of memory if you do!
This solution isn’t bad, but I have one big problem with it. The pool doesn’t know what type of component you’re pooling! This means that you have to do a GetComponent call every time you get an object out of the pool. It also means that there are no guarantees that the pool even HAS the component type you’re expecting; you can’t enforce it, so someone could mis-configure it in a prefab or a scene.
Can we do better? Yes! With generics!
Generics
Generics are a feature of the C# language. They let you design a class or write a method with a placeholder type, which means you can write classes or methods that work with any data type, and still remain type safe. Unity makes use of them, and in fact if you use Unity’s GetComponent<..>() methods you, are already using them yourself.
This line:
fooGameObject.GetComponent<FooComponent>()
gets the MonoBehaviour of type FooComponent which is on fooGameObject. How can this work? The Unity developers don’t know anything about your FooComponent. This syntax with the angled brackets indicates that the GetComponent method is a generic method which can work with any type (actually, specifically any MonoBehaviour type). When you call the method and put your type in the angled brackets, you tell the compiler to automatically generate a version of GetComponent that knows specifically about your type.
For more detailed information about generics, check out this introduction from Microsoft.
Improved Implementation
Let’s implement our object pool class using generics. First we need to define a generic version of the class that accepts a type name. We want to pool Unity components, so we’ll also add a constraint on the type which says that it must be a MonoBehaviour:
public class ObjectPool<T> : MonoBehaviour where T : MonoBehaviour
The where keyword defines the constraint. There are several different types of constraints we can specify. In our case we want the constraint that says “the type MUST derive from MonoBehaviour”.
Now that we have the class defined like this, we can use the generic type placeholder T anywhere that we want to refer to the type that the pool was created with:
public class ObjectPool<T> : MonoBehaviour where T : MonoBehaviour
{
// Prefab for this pool. The prefab must have a component of type T on it.
public T m_prefab;
// Size of this object pool
public int m_size;
// The list of free and used objects for tracking.
// We use the generic collections so we can give them our type T.
private List m_freeList;
private List m_usedList;
public void Awake()
{
m_freeList = new List(m_size);
m_usedList = new List(m_size);
// Instantiate the pooled objects and disable them.
for (var i = 0; i < m_size; i++)
{
var pooledObject = Instantiate(m_prefab, transform);
pooledObject.gameObject.SetActive(false);
m_freeList.Add(pooledObject);
}
}
}
Let’s now add two methods: one to get an object out of the pool and one to return an object back to the pool. Previously we passed GameObjects around because we didn’t know what type we would be dealing with. Now that we are using generics, we can use our placeholder T:
public T Get()
{
var numFree = m_freeList.Count;
if (numFree == 0)
return null;
// Pull an object from the end of the free list.
var pooledObject = m_freeList[numFree - 1];
m_freeList.RemoveAt(numFree - 1);
m_usedList.Add(pooledObject);
return pooledObject;
}
// Returns an object to the pool. The object must have been created
// by this ObjectPool.
public void ReturnObject(T pooledObject)
{
Debug.Assert(m_usedList.Contains(pooledObject));
// Put the pooled object back in the free list.
m_usedList.Remove(pooledObject);
m_freeList.Add(pooledObject);
// Reparent the pooled object to us, and disable it.
var pooledObjectTransform = pooledObject.transform;
pooledObjectTransform.parent = transform;
pooledObjectTransform.localPosition = Vector3.zero;
pooledObject.gameObject.SetActive(false);
}
And we’re done! You can see the full class over on github. Now, we can’t actually add this class to a GameObject yet. As it stands, the class is just a kind of template. It doesn’t really exist as any concrete code until we declare it somewhere with a concrete type.
Let’s assume that we have an Explosion MonoBehaviour which is on a prefab:
public class Explosion : MonoBehaviour
{
private ParticleSystem m_particleSystem;
public bool IsAlive { get { return m_particleSystem.IsAlive(); } }
public void Awake()
{
m_particleSystem = GetComponent<ParticleSystem>();
}
public void Spawn(Vector3 position)
{
gameObject.SetActive(true);
gameObject.transform.position = position;
m_particleSystem.Play();
}
}
We want to create a pool of Explosion objects. To do this, we must define a new class which derives from ObjectPool with the Explosion as our type parameter:
public class ExplosionPool : ObjectPool<Explosion>
{
}
And that’s it! You can now add ExplosionPool to a GameObject, and assign a prefab to it. The ObjectPool‘s m_prefab field will appear in the inspector, and it will only allow you to drop an Explosion component on it. It’s strongly typed!
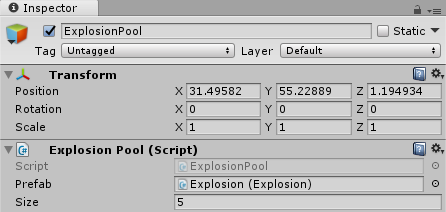
Now to spawn an explosion, you can do this:
public void SpawnExplosion(Vector3 position)
{
var explosion = m_explosionPool.Get();
if (explosion == null)
{
// The pool is empty, so we can't spawn any more at the moment.
return;
}
explosion.Spawn(position);
m_activeExplosions.Add(explosion);
}
In the above example we also keep track of the active explosions so we can return them to the pool when they are finished:
public void Update()
{
for (var i = 0; i < m_activeExplosions.Count - 1; i >= 0; i--)
{
var explosion = m_activeExplosions[i];
if (!explosion.IsAlive)
{
m_activeExplosions.RemoveAt(i);
m_explosionPool.ReturnObject(explosion);
}
}
}
Over on github I have a sample Unity project that demonstrates both the non-type-safe and type-safe methods. It’s a simple project that fires some particles from a pool when you click in the game window.
Feel free to hit me up on Twitter if you have any questions, or leave a comment below!